
Nowadays, AI and IoT have become widespread, and demand for semiconductors has increased; therefore, reduction of costs and improvement of production efficiency are needed in producing a single crystal silicon ingot which is a key material of semiconductors. A 300 mm diameter single crystal silicon ingot is mainly produced by the Czochralski (CZ) method. To keep high product quality, the crystal radius and the crystal growth rate must be controlled precisely by manipulating the heater input, the crystal pulling rate, and the crucible rise rate. Expecting that model predictive control would be useful to realize precise control, we constructed the gray-box model of an industrial 300 mm CZ process in our past research. To predict the control variables using the gray-box model, it is necessary to calculate the initial values of the melt temperature and the heater temperature, which are not measured in the industrial CZ process. When the initial values were determined by minimizing the error of the controlled variables between the measured values and the calculated values using the gray-box model just before the prediction period, the prediction accuracy at the end of the pulling process was lower than the other period. In the present work, we proposed the method of estimating the initial values by the statistical model, which was built with the data of past batches. Moving window partial least squares was used to develop the statistical model since it can cope with the time-varying characteristics of the CZ process, which originate from changes in the crystal length and the crucible position. The prediction accuracy was validated using the data of two batches, and the results showed that the proposed method could reduce the prediction error on average by 24% in comparison with the conventional method of using only the data of the current batch.
Soft-sensors were commonly used by engineers to predict quality variables that can only be infrequently sampled using sensors readings that are continuously available. Soft-sensor models can be data-driven or model driven. Data-driven models using non-parametric models such as artificial neural network are simple to develop given sufficient data. However, there are usually concerns about the extrapolation ability of the model beyond the data range. Model-based soft-sensor usually requires a physical model and an observer algorithm such as Kalman filter to estimate hidden state variables that cannot be directly measured. However, the effort required to develop a physical model is usually quite cumbersome. The recent development of deep learning opens up the possibility of development of more complex data-driven models that may be able to capture the actual system dynamics. For example, recurrent neural networks can be cast into a sequence to sequence (Seq2Seq) conversation models that can predict subsequent conversions based on past speech. In this work, such a Seq2Seq model formulated into an observer-predictor model that allows identification of hidden states of the system based on past actions and outcomes, and predict future outcomes based on current and future actions. The model is applied to quality predictions during mode-transition for the Tennessee Eastman Process. We found that after learning a few mode-transition data, the model could predict mode-changes that have not been encountered. An industrial distillation column separating c4/c5 product was also studied. Results show that not only the model could successfully predict quality variables in the product stream, but also has much better gain consistency than a simple back-propagation network.
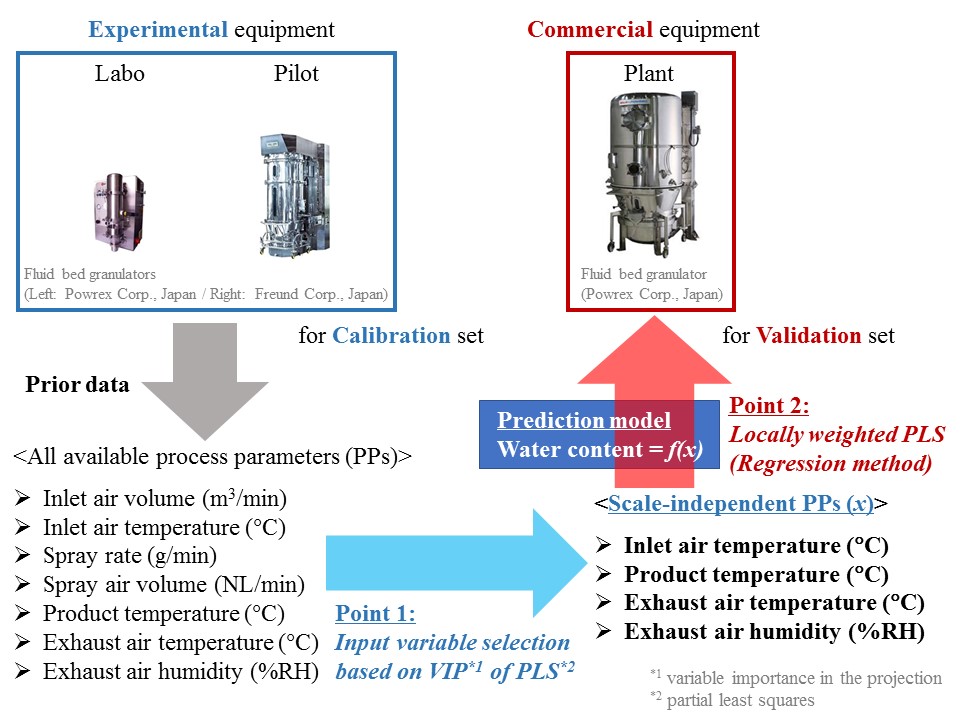
We propose an innovative monitoring method that can estimate the water content of granules by using only process parameters (PPs) obtained through standard instruments, e.g., thermometer and hygrometer. Thus, no investment is required to install specialized equipment such as a near-infrared (NIR) spectrometer, which is a common tool for process analytical technology (PAT). In addition, the proposed method is scale-free; the water content can be estimated with accuracy, regardless of the manufacturing scale, by selecting scale-independent PPs on the basis of variable importance in the projection (VIP) of partial least squares (PLS). The results of experiments have demonstrated the followings: 1) the prediction accuracy of the developed method is equivalent to a NIR spectra-based method commonly used in the pharmaceutical industry, 2) the developed method is robust against changes in manufacturing scale, and 3) the prediction accuracy of locally weighted partial least squares (LW-PLS), which can cope with both collinearity and nonlinearity, is significantly higher than that of PLS. The developed method is a powerful tool for scale-up study in batch processes because it enables scale-free monitoring for the water content of granules during fluid bed granulation at lower cost without additional investment. The developed method is expected to enhance the implementation of real-time monitoring of fluid bed granulation processes as a cost-effective alternative to the existing NIR method.
When designing a soft-sensor, we have to determine its parameters such as the number of latent variables of partial least squares (PLS) model. The parameters are usually selected to minimize the cross validation error, however, a soft-sensor model with one set of parameters should not cope with all the operation conditions. In such a case, the estimation error for some samples becomes large. In this research, to reduce the estimation error for those samples, the adaptive soft-sensor design method is proposed. In the proposed method, the leave-one-out cross validation error is calculated using the all the model construction samples. Then the samples with large estimation error are identified, and the model construction samples are divided into three groups. For each group, the parameters are optimized to minimize the leave-one-out cross validation error for the group. In addition, linear discriminant analysis (LDA) is conducted to find the discriminant axis in the input variable space. If the classification performance of LDA is not enough, kernel LDA is used. In online procedure, each of the model validation samples are classified into one of the three groups, and the parameters are adaptively selected. By using the selected parameters, the soft-sensor is developed and the output estimate is calculated. The usefulness of the proposed method was confirmed thorough its application to twelve industrial process data. The root mean square error (RMSE) was improved at most by 11.8%, and at least the same as the RMSE of conventional method using only one set of parameters.
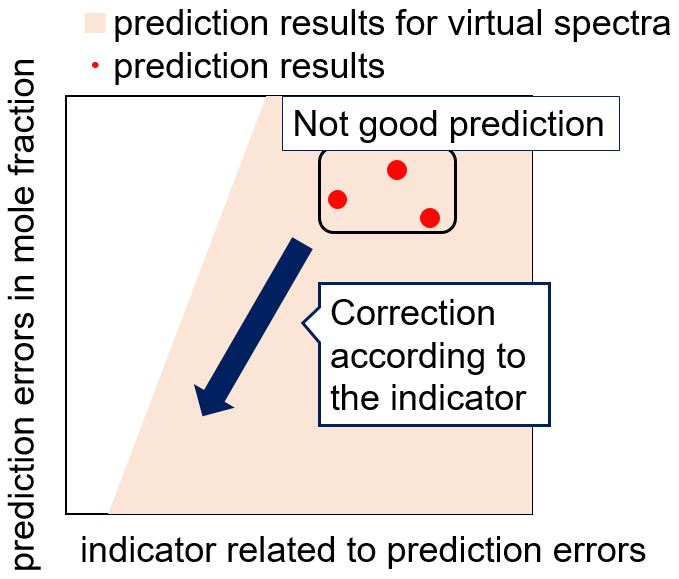
Continuous manufacturing (CM) in the pharmaceutical industry has been paid attention to, because it is expected to reduce the costs of manufacturing. One of technical hurdles in continuous manufacturing is establishment and maintenance of predictive models for process monitoring. Conventionally, calibration models with optic spectra such as infrared or Raman spectra have been used as the predictive models for process monitoring. The calibrated models predict product qualities such as active pharmaceutical ingredient's content, moisture content, particle size, and so on. However, any changes in rots, ratio of ingredients, or operation conditions may affect the relationship between sensor information and the product qualities, which results in deterioration of predictive models. Operators must update calibration models to assure predictive accuracy; however, calibration always requires data acquisition. Thus, the use of calibration models intrinsically increases economical costs. To tackle this problem, the authors have been attempting to propose a calibration-free approach with infrared spectra, which employs an equation in physics. To apply the calibration-free approach to real processes, it is important that a model provides accurate and reliable prediction. In this study, we propose a method to improve predictive accuracy of a calibration-free approach after assessing predictive errors using a rational indicator. We verified that the update method succeeded in non-ideal binary mixtures.
As the most important component of China's process industry, the refining and chemical industry is not only the pillar industry of economic and social development, but also an important cornerstone of the real economy. After decades of development, China's refining industry's production capacity has ranked second in the world, and has made great progress in product quality, cleanliness, supporting technology and process automation. With the rapid improvement of computer software and hardware, the development of machine-learning models and algorithm, the process industry has entered the era of big data. Also, with the impetus of the " Made in China 2025 " national strategy, intelligent refining related construction has been put on the agenda.
Modelling is the core of intelligent refining. The main feature of process industry contains high complexity, high dimensional and nonlinear characteristics, and so on. Centralized modeling will cause problems such as poor model performance. Therefore, system decomposition technology is built on model-based large-scale industrial process control strategies play an important role. EMD (Empirical Mode Decomposition) is an adaptive decomposition method proposed by Huang (1998) et al. for nonlinear processes. It has been effectively applied in different industrial fields and its effectiveness has been verified. CEEMD (Complete ensemble empirical mode decomposition) is an improved method of EMD. By adding two sets of white noise signals with opposite positive and negative, phenomenon of modal aliasing could be solved to some extent, and more multi-scale information in complex industrial processes can be better separate and identify.
CEEMD method is used to decompose the industrial FCC device in this work, and a soft sensor model is established at each sub-scale to capture more sub-scale information to achieve better overall measurement behavior. By comparing the results of decomposition modeling and centralized modeling, it can be found that the decomposition modeling method has advantages in measurement accuracy and better generalization performance.
Optimal control theory is applied to determine Pareto-optimal fronts for multi-objective optimization problems for seeded batch crystallization processes. A transformation of variables first suggested by Hofmann and Raisch (2010) is used to determine nearly-analytical expressions for the optimal supersaturation trajectory at each point on the Pareto front. A simple crystallization kinetic model for potassium nitrate crystallizing from water is used to illustrate the method.
Four sets of objective functions are considered in this work. Result show that if one objective is based on higher moments (e.g. the third moment of nucleated crystals) while the other is based on lower moments (e.g. the number mean crystal szie), the Pareto-optimal front is relatively wider, indicating significant competition between the two objectives. This is consistent with the conclusion of previous work (Tseng and Ward, 2017). In these cases, a constant growth rate trajectory may represent a good trade-off between two objectives. By contrast, if both objectives are based on higher or lower moments, the trade-off between the two objectives is less significant and the optimal trajectories for each single objective are similar.
This work demonstrates the inherent trade-off between objective functions in batch crystallization process and offers guidance for determining the “best” operating recipe when more than one objective is important. This understanding can facilitate the design of batch crystallization recipes.
References
Miller, S. M., Rawlings, J. B. (1994). Model identification and control strategies for batch cooling crystallizers. AIChE Journal, 40, 1312–1327.
Hofmann, S., Raisch, J. (2010). Application of optimal control theory to a batch crystallizer using orbital flatness, 16th Nordic Process Control Workshop, Lund, Sweden, 25–27 August 2010.
Tseng, Y. T., Ward, J. D. (2017). Comparison of objective functions for batch crystallization using a simple process model and Pontryagin's minimum principle. Computers & Chemical Engineering 99, 271-279.
