Despite the fact that the modern chemical plants are becoming more complex than they used to be, their operating procedures are still synthesized manually. Since this practice is laborious and error prone, it is desirable to develop a viable approach to automatically conjecture a sequence of executable actions to perform various tasks in realistic processes (Li et al., 2014). In this work, the automata (Cassandras and Lafortune, 2008) are adopted to model all components in the given system. To facilitate efficient procedure synthesis, the entire operation is divided into distinguishable stages and the intrinsic natures of each stage, e.g., stable operation, condition adjustment, material charging and/or discharging, etc., are then identified. The control specifications of every stage are also described with automata to set the target state, to create distinct operation paths, to restrict operation steps to follow the preferred sequences and to avoid unsafe operations. A system model and the corresponding observable event traces (OETs) can then be produced by synchronizing all aforementioned automata. The corresponding operating procedures can be formally summarized with sequential function charts (SFCs) according to these OETs. ASPEN Plus Dynamic has been used to verify the correctness of these SFCs in simulation studies. Since more than one procedure may be generated, these simulation results can also be adopted to rank them based on operability, safety and other economic criteria. Three examples, i.e., a semi-batch reaction process and the startup operations of continuous flash and distillation processes, are reported to demonstrate the effectiveness of the proposed synthesis strategy in practical applications.
References:
Cassandras, C. G., Lafortune, S., Introduction to Discrete Event Systems, 2nd edition, Springer, New York, NY, USA, 2008..
Li, J. H., Chang, C. T., Jiang, D., Systematic generation of cyclic operating procedures based on timed automata. Chem. Eng. Res. Des. 92, 139 – 155, 2014.
Gaussian process regression (GPR) has been gaining popularity due to its nonparametric Bayesian form. However, the traditional GPR model is designed for continuous real-valued outputs with a Gaussian assumption, which does not hold in some engineering application studies. For example, causal analysis of defects in steel products is to discover the relationships between a set of process variables and the number of defects, which is the count data output; the Gaussian assumption is invalid and the GPR model cannot be directly applied. Generalized Gaussian process regression (GGPR) can overcome the drawbacks of the conventional GPR, and it allows the model outputs to be any member of the exponential family of distributions. Thus, GGPR is more flexible than GPR. However, since GGPR is a nonlinear kernel-based method, it is not readily accessible to understand the effect of each input feature on the model output. To tackle this issue, the sensitivity analysis of GGPR (SA-GGPR) is proposed in this work. SA-GGPR aims to identify factors that exert higher influence on the model output by utilizing the information from the partial derivative of the GGPR model output with respect to its inputs. The proposed method was applied to a nonlinear count data system. The application results demonstrated that the proposed method is superior to the PLS-Beta, PLS-VIP, and SA-GPR methods in identification accuracy.
Plant alarm system notifies an operator of plant state deviations. A poor alarm system might cause sequential alarms, which are triggered in succession by a single root cause in chemical plant. The sequential alarms reduce the capacity of operators to cope with plant abnormalities because critical alarms are buried under numerous unimportant alarms. In this paper, we propose an identification method of sequential alarms in time stamped alarm data. The time stamped alarm data, which is composed of the occurrence alarm tags and time, is generally logged in a plant operation data. Repeated alarm occurrence patterns in plant operation data can be regarded as sequential alarms. The proposed method formulates the problem of identifying sequential alarms in plant operation data as the problem of mining repeated similar alarm subsequences. The identified sequential alarms help engineers to decrease the number of unnecessary alarms more effectively. The usefulness of the method is proved by a case study of an azeotropic distillation column.
In biopharmaceutical drug product manufacturing, establishing and maintaining a sterile production environment after a product change-over is essential to guarantee the product quality. Inside an isolator, both machine exterior and interior surface require intensive cleaning/disinfection, achieved through hydrogen peroxide decontamination, and clean-in-place (CIP)/sterilization-in-place (SIP), respectively. Numerous sensors are available to constantly monitor the process and provide real-time measurements of process variables. Generally, the stored sensor data is only used for backtracking actions. In our work, we use this stored data sets for establishing a predictive monitoring system of the process and performing early failure detection. The first step includes data preparation and data classification to failed and successful runs. Followed by the boundary definition of successful runs, i.e., “Golden Zones” and the prediction of the complete process performance following a few minutes of operation. The prediction is achieved through the application of machine learning algorithms, such as Random Forest and k-Nearest Neighbor. The final step compares and assesses the distance of the prediction to the “Golden Zone” boundaries to guide the decision-making process by the operators. We further explore opportunities to improve the machine learning algorithms to achieve the earliest possible failure detection points, i.e. to maximize the “time distance to the alarm”. This could be especially helpful in the case where failures can be detected before the introduction of the hydrogen peroxide to avoid the need to repeat the aeration process which is the most time-consuming step in the procedure.
Our approach was applied to a hydrogen peroxide decontamination process of an industrial filling line resulting in a 50% reduction of the number of erroneous runs to be repeated leading to significant operational time and financial savings.
In process industries, fault detection and diagnosis (FDD) are the first and the most important steps of uncovering abnormal situations and conducting timely corrections. For decades, many FDD methods have been developed and they can be briefly categorized into data-driven and model-based approaches. Recently, combining different kinds of methods to create hybrid approaches that could overcome disadvantages of individual methods has become an attempting research topic. In previous work, we had already achieved better fault detection performance by combining data-driven method with process knowledge. In this work, we expand this idea to create a hybrid fault diagnosis approach, by combining the use of principle component analysis (PCA), qualitative reasoning, and process-knowledge. PCA is utilized as the detection tool in this approach. Meanwhile, qualitative reasoning is used for diagnosis because it has the ability to estimate process behavior with limited and uncertain information, mimicking fault reasoning activity of expert engineers. Process knowledge are important operating information, such as mass or energy balance, non-measured process parameters, and controlled/manipulated variable ratio in a control loop. In this approach, process knowledge is enhanced into both PCA fault detection and diagnostic qualitative reasoning as an effort to achieve better FDD performance.
This approach is tested on Tennessee Eastman Process. Before the test, target process is divided into several units of operation to construct qualitative unit model, and most importantly, to extract operating information using process knowledge. The equations describing these process knowledge are established both quantitatively and qualitatively. The quantitative equations are used for detection propose in the same way as our previous work. The qualitative knowledge equations, as well as qualitative unit models, are represented in consistency matrices for diagnosis propose. As a result of online sample testing, this approach achieved better fault diagnosis effectiveness in comparison with traditional PCA-contribution plot method.
This study investigated the fault diagnosis performance of the entire and early detections for complicated chemical processes using the time-series recurrent neural networks (RNNs). The investigation included various layers and neuron nodes in RNNs using lean and rich training datasets and compared these RNNs with the artificial neural networks (ANNs). Further, the mechanism of classification of the RNNs was revealed in this study. The benchmark of the Tennessee Eastman process was used to demonstrate the performance of the recurrent neural network-based fault diagnosis model. The results showed that the ANNs and the RNNs required only a single hidden layer to reach their maximum accuracy, regardless of whether they use lean or rich training datasets. It was also observed that the ANNs required a higher number of the nodes than the RNNs.
Furthermore, the accuracy of the RNNs using the lean training dataset was equivalent to that of the ANNs using the rich training dataset. The variant RNN can distinguish between the fault types using the rich training dataset. We discovered that the classification mechanism of the ANNs was a priori classification, which was incapable of separating the fault types having similar features. RNNs did not have this limitation, as they were not a priori classification. In summary, the RNNs demonstrated a better performance with regard to the fault diagnosis in chemical processes than the ANNs, and were effective in classifying the fault types with subtle features when there is sufficient data.
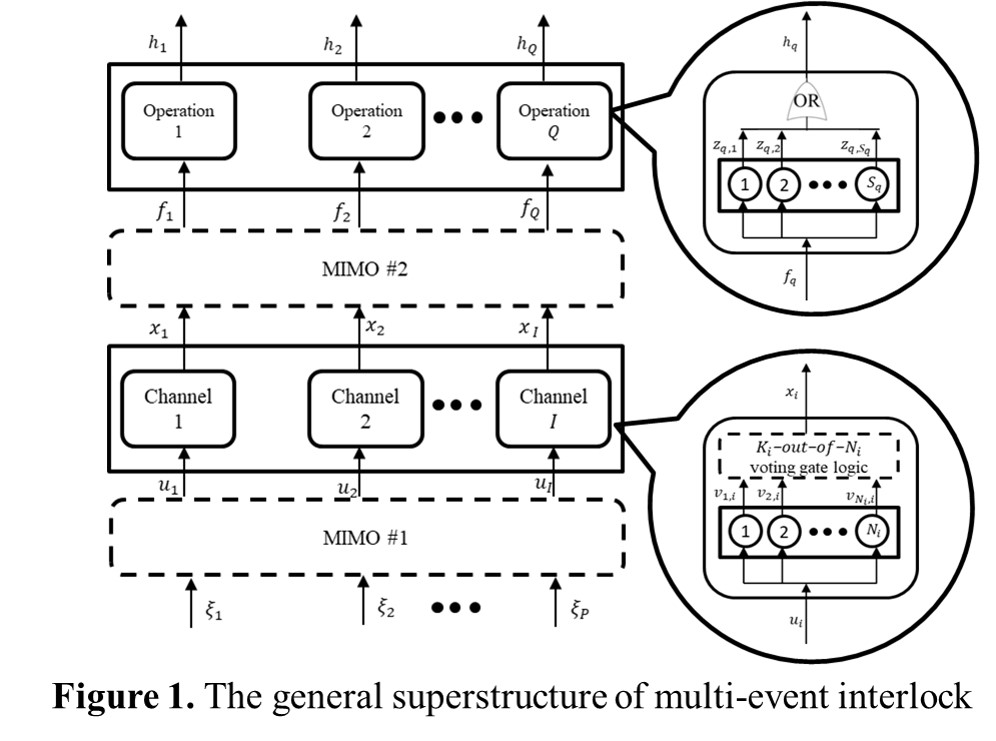
In order to mitigate the detrimental outcomes of process anomalies, modern chemical processes are generally equipped with safety interlocks. The conventional approach to design a protective system is usually aimed for prevention of the hazardous outcomes caused by a single abnormal event. However, since there may be more than one independent event producing multiple undesired effects within a realistic process, it is therefore necessary to develop a design methodology for the multi-input multi-output protective systems (see Figure 1). Specifically, the aim of this work is to construct a MINLP model to minimize the expected lifecycle loss of multi-event interlock and to generate the corresponding system configuration. In particular, the resulting specifications should include: (1) the number of online sensors in each alarm channel, (2) the voting-gate logic in each alarm channel, (3) the alarm logic, and (4) the number of shutdown elements for each shutdown operation. A simple example, i.e., the sump of a distillation column connected with a fired reboiler, is used in this paper to illustrate the aforementioned novel approach. From the optimization results, it can be observed that the proposed design strategy is indeed superior to the traditional one.